# Problemas de Pesquisa Aplicados {#cap-problemas-pesquisa-aplicados}
O ensino de Estatística muitas vezes começa pelo nome dos métodos: teste *t*, correlação, regressão, ANOVA, qui-quadrado. Essa ordem parece eficiente, mas cria um vício perigoso: o estudante aprende a procurar uma técnica que se encaixe nos dados antes de formular com precisão o problema de pesquisa. O resultado é uma estatística de cardápio, em que a pergunta científica é substituída por uma decisão operacional sobre qual botão apertar.
Este capítulo parte de outra direção. Em vez de perguntar "qual método devo aplicar?", vamos perguntar primeiro "qual decisão de pesquisa precisa ser tomada?", "qual quantidade precisa ser estimada?", "qual tipo de erro comprometeria a conclusão?" e "o desenho do estudo permite responder isso?". A estatística entra depois, como linguagem para formalizar a incerteza, não como uma lista de receitas.
Problemas aplicados raramente chegam organizados como exemplos de livro-texto. Eles misturam contexto, instrumentos, custos, vieses, variabilidade, objetivos práticos e consequências de decisão. Por isso, cada tópico deste capítulo será guiado por um caso real ou plausível, com tags de área e assunto para deixar claro o contexto de aplicação.
## Comparação de métodos de medição em medicina {#sec-comparacao-metodos-medicao-medicina}
**Tags:** `medicina`, `comparação-de-métodos`, `concordância`, `viés`, `repetibilidade`
Este tópico é baseado no artigo "Measurement in Medicine: The Analysis of Method Comparison Studies", de D. G. Altman e J. M. Bland (1983). O problema discutido pelos autores aparece com frequência em pesquisas médicas: um pesquisador quer saber se um novo método de medição, mais barato, rápido ou simples, pode substituir um método já estabelecido. Exemplos incluem medidas de pressão arterial, idade gestacional ou volume cardíaco.
A pergunta de pesquisa não é "os dois métodos estão correlacionados?". Em geral, eles devem estar correlacionados, pois tentam medir a mesma quantidade. A pergunta relevante é: **os métodos concordam o suficiente para que um possa substituir o outro no uso clínico pretendido?**
Essa mudança de pergunta altera toda a análise. Comparar médias pode esconder grandes discordâncias individuais: dois métodos podem ter a mesma média e ainda assim discordar muito paciente a paciente. Calcular apenas a correlação também é insuficiente, porque a correlação depende da variabilidade entre indivíduos; uma amostra com pacientes muito diferentes pode gerar uma correlação alta mesmo quando a concordância clínica é ruim. Regressão simples, quando usada mecanicamente, desloca o foco para associação e predição, mas não responde diretamente se as diferenças entre métodos são aceitáveis.
O caminho estatístico deve começar pela estrutura do problema. Primeiro, avaliar a repetibilidade de cada método: se o mesmo método medisse o mesmo paciente novamente, quanta variação seria esperada? Depois, comparar diretamente as diferenças entre os métodos para cada indivíduo. A média dessas diferenças descreve o viés relativo; a dispersão das diferenças descreve o erro de concordância. Um gráfico das diferenças contra a média das duas medidas ajuda a visualizar viés, outliers e mudanças de erro ao longo da escala de medição.
O ponto central do caso é pedagógico: o método estatístico correto não nasce do formato da tabela, mas da pergunta substantiva. Em medicina, a decisão final não é se um coeficiente é significativo; é se o erro observado é pequeno o bastante para não prejudicar uma decisão clínica.
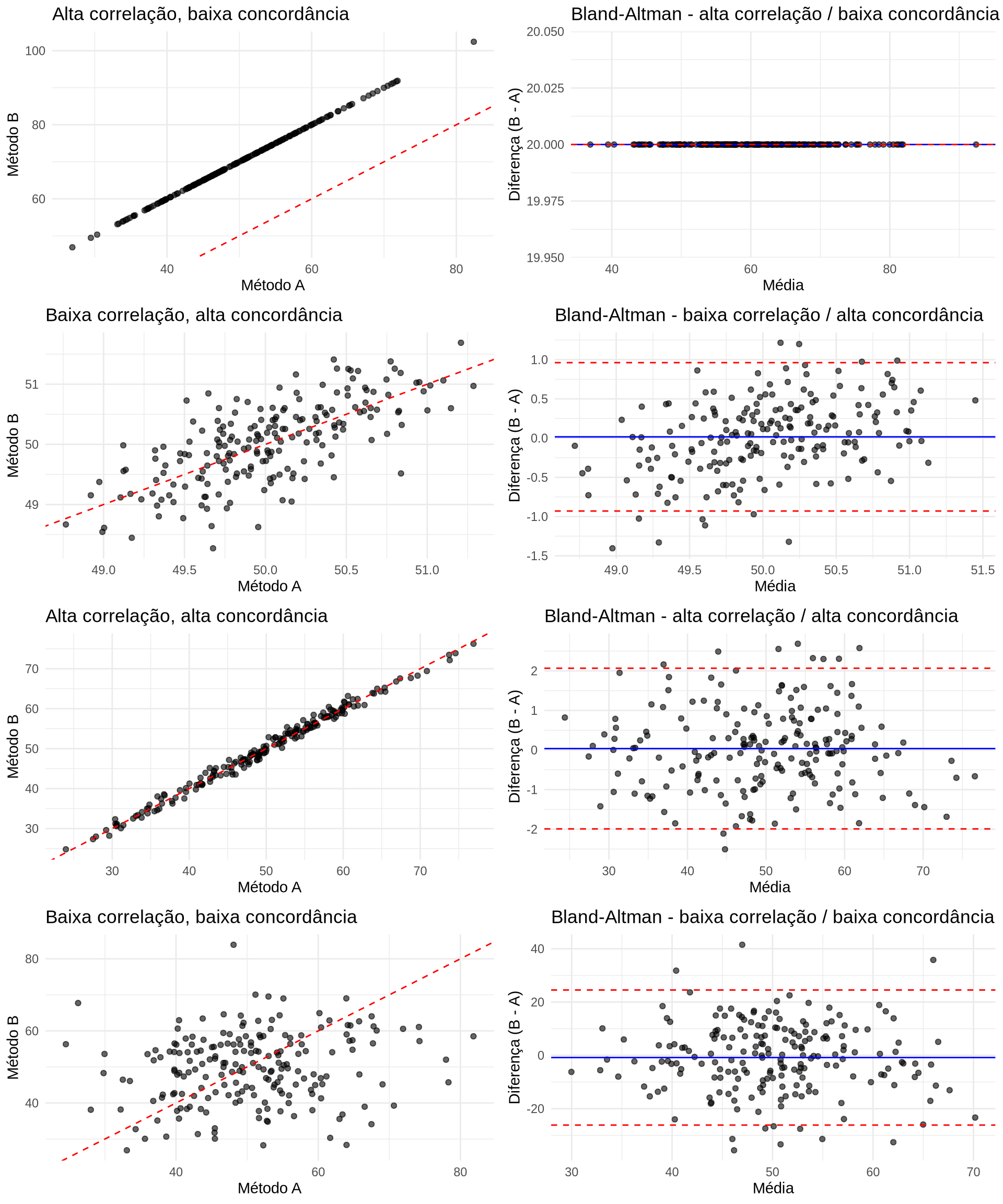
### Concordância × Correlação {#sec-concordancia-correlacao}
Uma forma simples de separar os conceitos é simular quatro situações. O código abaixo reproduz a lógica do script `Desktop/josmar simulacao concordancia.r`: em cada cenário comparamos um gráfico de dispersão com a linha de identidade contra um gráfico de Bland-Altman. O código fica recolhido por padrão, mas pode ser expandido pelo leitor.
```{r}
#| label: fig-concordancia-correlacao
#| echo: true
#| code-fold: true
#| code-summary: "Mostrar código da simulação"
#| message: false
#| warning: false
#| fig-width: 10
#| fig-height: 12
#| fig-cap: "Correlação e concordância em quatro cenários simulados."
library(ggplot2)
set.seed(123)
plot_scatter_identity <- function(df, titulo) {
ggplot(df, aes(x = x, y = y)) +
geom_point(alpha = 0.6) +
geom_abline(
slope = 1, intercept = 0,
color = "red", linetype = "dashed"
) +
labs(title = titulo, x = "Método A", y = "Método B") +
theme_minimal()
}
plot_bland_altman <- function(df, titulo) {
df$media <- (df$x + df$y) / 2
df$diff <- df$y - df$x
mean_diff <- mean(df$diff)
sd_diff <- sd(df$diff)
ggplot(df, aes(x = media, y = diff)) +
geom_point(alpha = 0.6) +
geom_hline(yintercept = mean_diff, color = "blue") +
geom_hline(
yintercept = mean_diff + 1.96 * sd_diff,
linetype = "dashed", color = "red"
) +
geom_hline(
yintercept = mean_diff - 1.96 * sd_diff,
linetype = "dashed", color = "red"
) +
labs(
title = paste("Bland-Altman -", titulo),
x = "Média", y = "Diferença (B - A)"
) +
theme_minimal()
}
x1 <- rnorm(200, 50, 10)
y1 <- x1 + 20
df1 <- data.frame(x = x1, y = y1)
x2 <- rnorm(200, 50, 0.5)
y2 <- x2 + rnorm(200, 0, 0.5)
df2 <- data.frame(x = x2, y = y2)
x3 <- rnorm(200, 50, 10)
y3 <- x3 + rnorm(200, 0, 1)
df3 <- data.frame(x = x3, y = y3)
x4 <- rnorm(200, 50, 10)
y4 <- rnorm(200, 50, 10)
df4 <- data.frame(x = x4, y = y4)
plots <- list(
plot_scatter_identity(df1, "Alta correlação, baixa concordância"),
plot_bland_altman(df1, "alta correlação / baixa concordância"),
plot_scatter_identity(df2, "Baixa correlação, alta concordância"),
plot_bland_altman(df2, "baixa correlação / alta concordância"),
plot_scatter_identity(df3, "Alta correlação, alta concordância"),
plot_bland_altman(df3, "alta correlação / alta concordância"),
plot_scatter_identity(df4, "Baixa correlação, baixa concordância"),
plot_bland_altman(df4, "baixa correlação / baixa concordância")
)
grid::grid.newpage()
grid::pushViewport(grid::viewport(layout = grid::grid.layout(4, 2)))
for (i in seq_along(plots)) {
print(
plots[[i]],
vp = grid::viewport(
layout.pos.row = ceiling(i / 2),
layout.pos.col = ifelse(i %% 2 == 1, 1, 2)
)
)
}
```
O quarto caso é o mais útil para discutir o erro interpretativo. Nele, os dois métodos foram simulados com a mesma média populacional, mas sem concordância par a par. O teste t para médias simples formula:
- $H_0: \mu_A = \mu_B$, isto é, as médias marginais dos métodos são iguais.
- $H_1: \mu_A \ne \mu_B$, isto é, as médias marginais dos métodos são diferentes.
Esse teste trata as medições dos métodos A e B como se fossem duas amostras independentes e pergunta apenas se uma média global difere da outra. O teste t pareado formula:
- $H_0: \mu_D = 0$, em que $D = A - B$, isto é, o viés médio entre os métodos é zero.
- $H_1: \mu_D \ne 0$, isto é, há viés médio entre os métodos.
O teste pareado respeita que cada par de medidas pertence ao mesmo indivíduo, mas ainda assim testa apenas viés médio. Ele não prova concordância clínica; para isso precisamos olhar a dispersão das diferenças.
```{r}
#| label: tbl-testes-t-caso-4
#| echo: true
#| code-fold: true
#| code-summary: "Mostrar código dos testes t do caso 4"
#| message: false
#| warning: false
teste_t_medias <- t.test(x4, y4, paired = FALSE)
teste_t_pareado <- t.test(x4, y4, paired = TRUE)
diff_b_menos_a <- y4 - x4
resumo_caso_4 <- data.frame(
medida = c(
"Correlação",
"Média do método A",
"Média do método B",
"Diferença média (B - A)",
"Desvio padrão das diferenças",
"Limite inferior de concordância",
"Limite superior de concordância",
"p-valor: teste t para médias simples",
"p-valor: teste t pareado"
),
valor = c(
cor(x4, y4),
mean(x4),
mean(y4),
mean(diff_b_menos_a),
sd(diff_b_menos_a),
mean(diff_b_menos_a) - 1.96 * sd(diff_b_menos_a),
mean(diff_b_menos_a) + 1.96 * sd(diff_b_menos_a),
teste_t_medias$p.value,
teste_t_pareado$p.value
)
)
knitr::kable(
resumo_caso_4,
digits = 3,
caption = "Resumo do caso 4: baixa correlação e baixa concordância."
)
```
No caso 4, o teste t para médias simples não rejeita $H_0$ porque as médias globais dos métodos são parecidas. Se a análise parasse ali, poderíamos concluir incorretamente que os métodos são equivalentes. Essa é a armadilha: igualdade de médias não implica concordância entre medidas individuais.
O teste pareado também não rejeita a hipótese de viés médio zero, mas ele deixa claro que a pergunta é sobre as diferenças par a par. O gráfico de Bland-Altman e os limites de concordância mostram o problema substantivo: as diferenças individuais podem variar aproximadamente de -26 a 25 unidades, uma amplitude grande para muitos contextos clínicos. Portanto, a conclusão correta não é "os métodos são iguais"; é "não há evidência de viés médio relevante nesta simulação, mas a concordância individual é ruim".